CRIC: A VQA Dataset for Compositional Reasoning on Vision and Commonsense
Overview
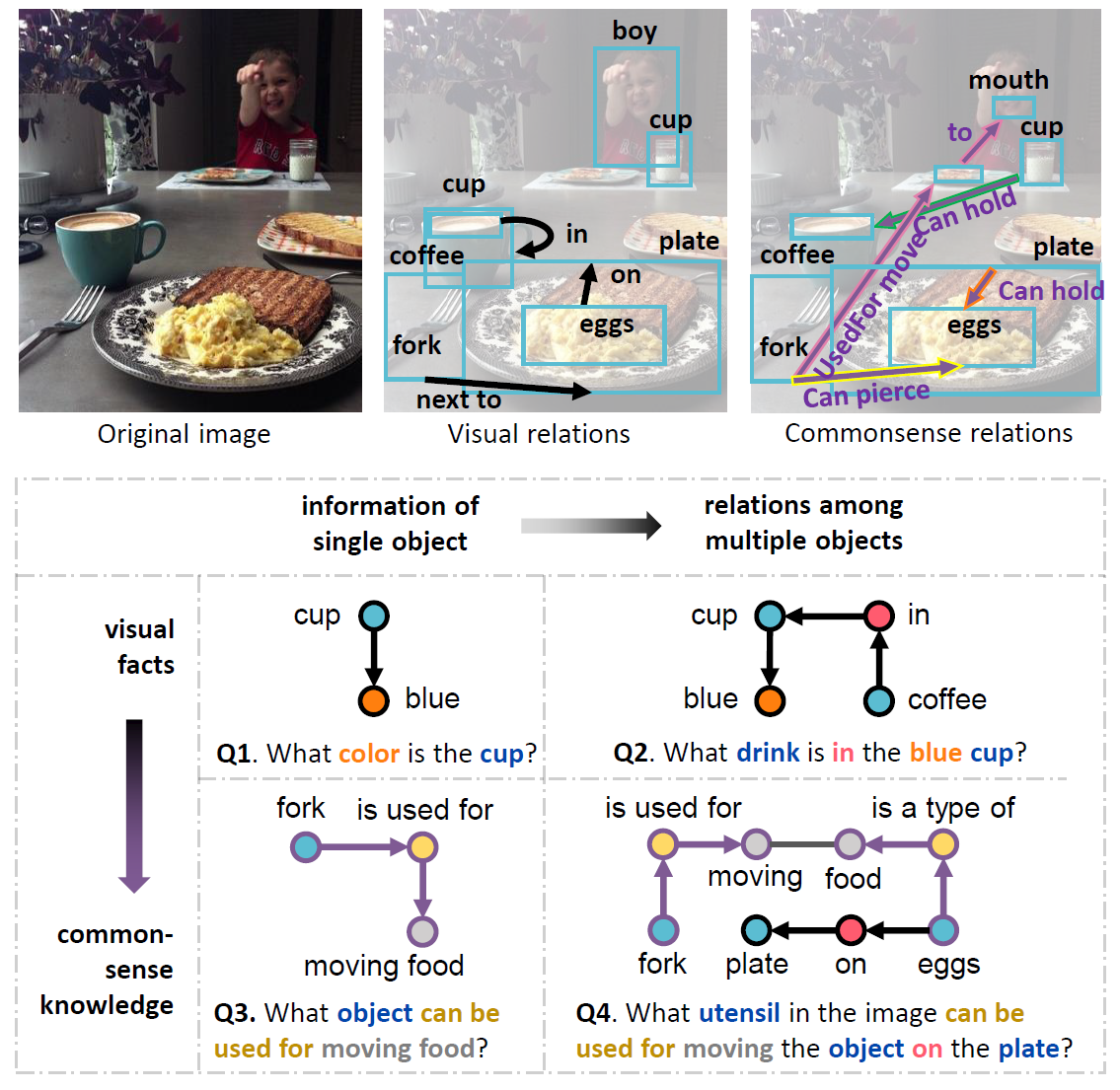
CRIC contains
compositional questions to evaluate the ability of a model on alternatively inferring on vision and
commonsense.
Statistics
- 96K images from Visual Genome
- 494K automatically generated questions
- 3.4K collected knowledge items from ConceptNet and Wikipedia
- Rich additional annotations, e.g., question related scene graph & knowledge graph, reasoning steps, etc.
Annotations
-
The question files (train_questions.json, val_questions.json, test_v1_questions.json) consist of a list of question items where each item’s structure is as follows:
{ "sub_graph": # a dictionary for recording the sub-graph related to generating the question { "relations": list, # a list for recording the relationships (from Visual Genome annotations) used for generating the question "attributes": list, # a list for recording the attributes (from Visual Genome annotations) used for generating the question "knowledge_items": list, # a list for recording the knowledge items (from ConceptNet) for generating the question }, "image_id": int, # an image id in Visual Genome dataset "question": str, "question_id": str, "question_type": str, "answer": str, "target": list, # a list of object ids indicating the ground-truth results of the gruonding "program": # a list representing the reasoning steps (function layout) of answering a question. [{"function": str, # a function name, e.g. "Find" "text_input": list, # a text input of function, e.g. the text input ["car", "red"] for "Find" function, indicates finding the red car "output": list, # a list of object ids indicating the ground truth output of the current function }, ...], "wrong_part": str, # a string for explaining the reason if the answer is "no" } -
The scene graph of all images are stored in a JSON file scene_graphs.json (unzip “scene_graphs.zip” to get this file) containing relationship, attribute and object annotation. And the format is similar to the annotations in Visual Genome.
-
The knowledge items are stored in knowledge_graph.json, where each item is represeted in triplet format, <head, relation, tail>.
-
The object features are stored in two files, cric_objects.zip and cric_objects.z01. Place these two files in one folder and unzip cric_objects.zip to get cric_objects.h5. The structure of cric_objects.h5 is:
cric_objects = { "features": float, # the faster r-cnn features (bottom-up features) of for up to 100 objects with ground truth bounding boxes. Size (number of images, 100, 2048). "object_id": int, # the ids of objects in images. Size (number of images, 100) } -
The basic information of the images are stored in cric_objects_info.json. The structures of the file is as follows:
cric_objects_info = { "image_id": # a string indicating the image id of Visual Genome { "width": int, "height": int, "objectsNum": int, "index": int, # indicating the position of the image features in cric_object_features.h5 } }
For downloading our dataset, you should use your institutional email address to send an email to Prof. Ruiping Wang and Dr. Difei Gao to state your specific research purpose. When we receive your email, we will provide the download link to you.
Evaluation
The models are evaluated with two metrics, answer correctness and grounding correctness:
final_score = answer_correctness * grounding_correctnessCitation
The CRIC dataset is released for research purpose only. By using the CRIC dataset, you are recommended to refer to the following paper:
@article{gao2023cric,
title={CRIC: A VQA Dataset for Compositional Reasoning on Vision and Commonsense},
author={Gao, Difei and Wang, Ruiping and Shan, Shiguang and Chen, Xilin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence,
year={2023},
volume={45},
number={5},
pages={5561-5578},
doi={10.1109/TPAMI.2022.3210780}
}Contact
-
Ruiping Wang, Institute of Computing Technology, Chinese Academy of Sciences
-
Difei Gao, Institute of Computing Technology, Chinese Academy of Sciences